META称Llama 3击败了包括Gemini在内的大多数其他模型
该公司在一篇博客文章中表示, Meta的下一代大型语言模型Llama今天向AWS等云提供商和Hugging Face等模型库发布,其性能优于目前大多数人工智能模型。

Llama 3目前有两个模型权重,分别是8B和70B参数。(B代表数十亿,代表模型的复杂程度以及它所理解的训练的多少。)到目前为止,它只提供基于文本的响应,但Meta表示,这些是前一个版本的“重大飞跃”。Llama 3在回答提示时表现出更多的多样性,在拒绝回答问题时有更少的错误拒绝,并能更好地推理。Meta还表示,Llama 3理解的指令比以前多,写的代码比以前好。
在帖子中, Meta声称Llama 3的两个尺寸在某些基准测试中击败了类似尺寸的模型,如谷歌的Gemma和Gemini 、 Mistral 7B和Anthropic的Claude 3 。在通常衡量一般知识的MMLU基准测试中, Llama 3 8B的表现明显优于Gemma 7B和Mistral 7B,而Llama 3 70B略微领先于Gemini Pro 1.5 。

(值得注意的是,Meta的2700字的帖子没有提到OpenAI的旗舰模型GPT-4。)
还应该注意的是,基准测试人工智能模型,虽然有助于了解它们有多强大,但并不完美。用于基准测试模型的数据集已被发现是模型训练的一部分,这意味着模型已经知道评估人员将问它的问题的答案。
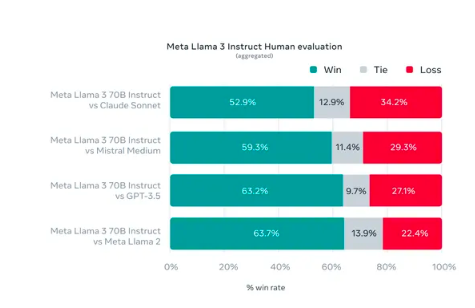
Meta表示,人类评估者也给Llama 3打了比其他模型更高的分数,包括OpenAI的GPT-3.5。Meta表示,它为人类评估者创建了一个新的数据集,以模拟可能使用Llama 3的真实场景。这个数据集包括寻求建议、总结和创造性写作等用例。该公司表示,致力于该模型的团队没有访问这个新的评估数据,它不会影响该模型的性能。
Meta在其博客中写道:“这个评估集包含1800个提示,涵盖了12个关键用例:征求意见、头脑风暴、分类、封闭式问题回答、编码、创意写作、提取、居住在一个角色/人物中、开放式问题回答、推理、重写和总结。”
Llama 3预计将获得更大的模型大小(可以理解更长的指令和数据串),并能够进行更多的多模态响应,如“生成图像”或“转录音频文件”。 Meta表示,这些更大的版本,超过400B参数,可以比较小的版本的模型学习更复杂的模式,目前正在训练,但初步性能测试表明,这些模型可以回答许多基准测试提出的问题。
不过, Meta没有发布这些更大模型的预览,也没有将它们与GPT-4等其他大型模型进行比较。
