高通祭出骁龙X系列!PC市场要变天
2024,AI PC元年。随着生成式AI的热潮席卷全球,生成式AI和大语言模型的飞跃式发展正在深刻改变个人生活与工作模式,加速各行各业智能化转型。

同时,生成式AI的快速发展和广泛应用正在推动人工智能技术向多模态转变,这意味着未来的AI模型将能够更好地理解和处理多种类型的数据,从而在移动PC等设备上提供更加丰富和个性化的用户体验——这也是移动PC新的发展机遇。
从目前的趋势来看,AI的进化与普及离不开软硬件的共同驱动,而以智能手机、PC为代表的终端设备作为用户接入AI的最直接载体已经成为AI升级落地的重要突破口。
在智能手机厂商纷纷响应的同时,PC行业与其深度融合只是时间问题。
根据数据分析公司Gartner的定义,AI PC是指配备了专用的AI加速器或核心、神经处理单元(NPUs)等其他单元的计算机,旨在优化和加速设备上的AI任务。
这样可以提供更好的性能和效率,处理AI和生成式AI工作负载时无需依赖外部服务器或云服务。市面上已经出现了第一批搭载具备NPU的AI PC,相较于2023年,2024年的AI PC阵容已经初见规模。
Gartner公司的最新预测显示,到2024年底,人工智能(AI)个人电脑(PC)和生成式人工智能(生成式AI)智能手机的全球出货量预计将从2023年的2900万台增长至2.95亿台。
而在今年年中,我们将看到搭载骁龙X Elite和骁龙 X Plus的AI PC上市。
NPU和异构计算的重要意义
生成式AI变革已经到来。随着生成式AI用例需求在有着多样化要求和计算需求的垂直领域不断增加,我们显然需要专为AI定制设计的全新计算架构。

这首先需要一个面向生成式AI全新设计的神经网络处理器(NPU),同时要利用异构处理器组合,比如中央处理器(CPU)和图形处理器(GPU)。
通过结合NPU使用合适的处理器,异构计算能够实现最佳应用性能、能效和电池续航,赋能全新增强的生成式AI体验。
生成式AI多样化的计算需求需要不同的处理器来满足。在AI PC运行时,CPU主要应对顺序控制和即时性运算,适用于需要低时延的应用场景。
GPU擅长面向高精度格式的并行数据流处理,比如对画质要求非常高的图像以及视频处理。而NPU则更擅长与AI运算直接关联的标量、向量和张量数学运算,可用于核心AI工作负载。
不同的AI运算运行在适合的芯片上时才能够最大化效率,优秀的NPU设计能够为处理这些AI工作负载做出正确的设计选择。
当下,要满足生成式AI的多样化要求和计算需求,整合不同的处理器的算力是必然。高通的NPU并非独立存在的,而是与CPU、GPU共同构成了异构计算体系。
高通AI引擎包括高通Hexagon NPU,它是高通AI引擎中的关键处理器,通过定制设计NPU以及控制指令集架构(ISA),高通能够快速进行设计演进和扩展,解决瓶颈问题并优化性能。
此外,高通AI引擎还包括高通Adreno GPU、高通Oryon CPU、高通传感器中枢和内存子系统。
这些处理器为实现协同工作而设计,能够在终端侧快速且高效地运行AI应用。在四大核心模块的通力协作下,高通异构计算能够实现最佳应用性能、能效和电池续航,实现生成式AI终端性能的最大化。
而这一切都会在骁龙X系列PC平台上展现出强大的竞争力。
混合AI需要解决性能和功耗的问题
一如高通在去年发布的《混合AI是AI的未来》白皮书,高通公司总裁兼CEO安蒙在4月举行的联想创新科技大会上再次强调了“混合AI是AI的未来”这一论断。
高通认为,混合AI可以在终端侧和云端同时利用AI,通过高性能连接来分配和协调工作负载,从而带来更加智能的个性化用户体验。因此,连接和高性能低功耗计算的优先级被大大提高。
基于这样的出发点,高通以骁龙X Elite和X Plus为AI PC领域交上答卷。
对于性能和功耗的调教,骁龙在手机领域成功了非常丰富的经验——无论是第一代骁龙8+、第二代骁龙8还是第三代骁龙8,多年来骁龙对性能功耗最佳平衡的追求策略已经延伸到PC领域。
我们甚至可以先不讨论旗舰级的骁龙X Elite,让我们再回头看看刚刚发布不久的骁龙X Plus展现出的惊人的性能表现和极为出色的能效比。
骁龙X Plus采用骁龙X Elite同样的4纳米制程工艺,其Oryon CPU有10个定制的高性能核心,最高主频达3.4GHz,总缓存42MB。
CPU性能方面,对比同样基于ARM架构的苹果M3芯片,骁龙X Plus具备明显优势。在GeekBench 6测试中,骁龙X Plus的多线程CPU性能可以领先M3芯片近10%。而骁龙X Elite的领先幅度则可以达到28%。
同样是在Geekbench多线程测试中,骁龙X Plus表现也要优于英特尔酷睿Ultra 7 155H,在达到相同峰值性能时,骁龙X Plus的功耗比酷睿Ultra 7 155H低54%。
而在Cinebench 2024多线程测试中,骁龙X Plus在相同功耗下的CPU性能领先后者达28%。
而限定同样的相同峰值性能时,骁龙X Plus的功耗比后者低39%,这将在用户使用设备时转化成感知明显的续航优势。
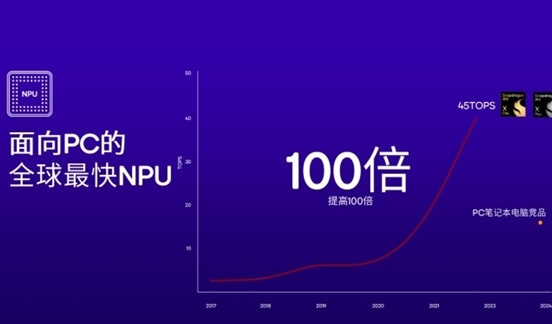
GPU方面,Adreno GPU速度高达3.8TFLOPS。在WildLife Extreme测试中,骁龙X Plus仅用不足20W的功耗就实现了竞品近40W功耗才实现的性能释放。而加持了骁龙X Elite同样的Hexagon NPU的骁龙X Plus也能够实现高达45TOPS的强大算力。

这一NPU是面向PC的全球最快的NPU,相较于PC、笔记本电脑竞品,AI性能提高100倍,可以赋予轻薄笔记本设备用远低于竞品的功耗实现数倍于竞品的AI计算速度。
骁龙生态正在构建
除了提供领先的硬件平台设计,高通也推出了一个跨平台、跨终端、跨操作系统的统一软件栈——高通AI软件栈(Qualcomm AI Stack)。
据高通公司AI产品技术中国区负责人万卫星介绍,高通AI软件栈支持所有目前主流的训练框架和执行环境,为开发者提供不同级别、不同层次的优化接口以及完整的编译工具链,让开发者可以在骁龙平台上更加高效地完成模型的开发、优化和部署。
值得一提的是,高通AI软件栈是一个跨平台、跨终端的统一解决方案,所以开发者只要在高通和骁龙的一个平台上完成模型的优化部署工作,便可以将这部分工作迁移到高通和骁龙的其他所有产品上。
这将极大提升开发者的开发效率,同样也有助于将产品快速铺开,对开发者来说尤其利好。
此外,在今年的MWC2024期间,高通还发布了高通AI Hub。
该模型库为开发者提供了超过75个主流的AI和生成式AI模型,比如Whisper、ControlNet、Stable Diffusion和Baichuan-7B,可在不同执行环境(runtime)中打包,在不同形态终端中实现出色的终端侧AI性能、降低内存占用并提升能效。
高通针对所有模型进行了优化,使它们可以充分利用高通AI引擎内所有核心(NPU、CPU和GPU)的硬件加速能力,大幅提升推理速度。
开发者可将这些模型无缝集成进应用程序,缩短产品上市时间,发挥终端侧AI部署的即时性、可靠性、隐私、个性化和成本优势。
目前,高通AI Hub已经支持超过100个模型,包括语言、文本和图像在内的生成式AI模型以及例如图像识别、图像分割,自然语言理解、自然语言处理这样的传统AI模型。
而在应用前端,高通为消费者们带来了Snapdragon Seamless。通过Snapdragon Seamless,不同系统的多个终端可以协同运作,用户可以使用鼠标在手机、PC和平板上无缝拖动。文件和窗口可跨终端放置。
耳机可根据播放的优先级进行智能切换等等。这将是一个串联终端的全面生态,除了已有的PC、手机、平板、TWS耳机等,其覆盖设备将扩展至XR、汽车和物联网平台,实现与用户生活相关联的全部终端的连接。
写在最后
高通很清楚,AI生态的构建并非朝夕所能成。而高通也正在构建从底层到生态的计算体系,为厂商、消费者带来了Hexagon NPU、第三代骁龙8、骁龙X Elite等顶尖算力支持。
高通也并不被所谓的等级划分所框住,高通希望通过快速丰富产品矩阵为广大用户带来更加丰富的选择。
正如骁龙X Plus的定位,在回答媒体采访时,高通技术公司产品管理副总裁Nitin Kumar表示,骁龙X Plus能够将骁龙的产品领导力扩展至更多终端,惠及更多用户。无论是骁龙X Elite还是X Plus都能在其所在的产品层级提供顶级体验。
包括合作伙伴与众多开发者,高通也为他们设计了包括高通AI软件栈(Qualcomm AI Stack)和AI Hub在内的众多开发套件和工具库,助力开发者的同时也是在加速生态完善,最终使最广大消费者获益,让骁龙生态圈更加完备。
搭载骁龙X Elite和骁龙X Plus的新品都将在今年年中正式上市,今年的COMPUTEX一定热闹非凡。既然混合AI是AI的未来,高通已经在通过前面数十年的厚积薄发告诉我们,AI PC的未来同样有着高通的话语权。
